
آشنایی با کتابخانه Pandas

کتابخانه pandas یکی از مهمترین کتابخانهها در زمینه ماشین لرنینگ و دیتاساینس میباشد.
آنچه در این مقاله خواهید آموخت:
کتابخانه Pandas چیست؟
نصب کتابخانه Pandas
فراخوانی Pandas
انواع ساختار داده در Pandas
نحوه استخراج اطلاعات از داده به کمک Pandas
مثال بر روی یک دیتای واقعی
دستورات پرکاربرد
کتابخانه Pandas چیست؟
کتابخانه ی اوپن سورس Pandas، یکی از معروفترین و محبوبترین کتابخانه های Python در علم داده است. این کتابخانه بر روی کتابخانهی NumPy توسعه داده شده، و محبوبیت آن به خاطر آسان سازی کار با ساختارهای مختلف داده می باشد.
کتابخانهی Pandas دارای ابزارهای متعددی برای فراخواندن انواع داده، پاک سازی، تصویر سازی، اعمال تغییرات دلخواه، و سایر عملیاتهای ممکن با داده هاست.
در مقاله پیش رو، به معرفی و بررسی پرکاربردترین ابزارهای Pandas، نحوه ی عملکرد هرکدام، و کاربرد آن ها در کار با دیتاهای واقعی می پردازیم.
نصب کتابخانه Pandas
نصب از طریق Anaconda
راحت ترین روش برای نصب Pandas این روش است. Anaconda یک پلتفرم از Python است که برای آنالیز داده و انواع محاسبات توسعه داده شده است. نکتهی مثبت استفاده از این روش، نصب شدن همزمان سایر کتابخانه های مورد استفاده در علم داده (نظیر NumPy، Matplotlib، و …) است، و دیگر نیاز به نصب جداگانهی آنها نیست. برای یادگیری نحوه ی نصب Anaconda به این لینک مراجه کنید.
نصب از طریق PyPI
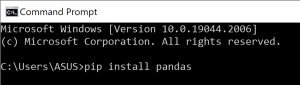
برای نصب از این طریق، دستور زیر را در pip، و یا command prompt ویندوز اجرا کنید.
سایر روش ها
برای استفاده از سایر روش های نصب Pandas، به این لینک در سایت خود این کتابخانه مراجعه کنید.
فراخوانی Pandas
روش استاندارد و متداول فراخوانی کتابخانه ی Pandas به شکل زیر است:
![]()
در این دستور به کمک import عملیات فراخوانی یک کتابخانه صورت میگیره و بعد از معرفی خود pandas و از دستور as pd عملیات مختصرسازی صورت میگیرد و از این جا به بعد تنها با صدا کردن pd، کتابخانه pandas فراخوانی میشود.
انواع ساختار داده در Pandas
برای کار با داده ها در Pandas، از دو ساختار DataFrame و Series استفاده می شود. DataFrame در واقع یک ساختار دو بعدی از داده هاست. داده های ذخیره شده در این ساختار قابل تغییر هستند (mutable)، و هر ستون / سطر، لیبل مخصوص به خود را دارد.
برای ساخت دیتافریم، از دستور pd.DataFrame میتوان استفاده کرد :
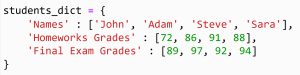
در بالا، یک dictionary شامل اسامی دانش آموزان، نمرات تکالیف آن ها و نمره ی امتحان پایانی آنها، تعریف کرده ایم.
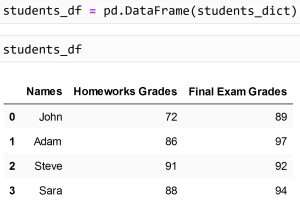
همانطور که در سلول های بالا مشاهده می شود، با استفاده از Pandas، و همچنین dictionary که قبلا تعریف کردیم، یک دیتافریم ساختیم. در دیتافریم بالا، لیبل ستون ها با عنوان (Names, Homeworks, Grades, Final Exam Grades) و لیبل سطرها، که به آن index نیز گفته می شود، مشخص شده است.
توجه کنید که ساخت دیتافریم به استفاده از dictionary محدود نیست، و میتوان با استفاده از list ها، تعدادی از dictionary ها، و … دیتافریم را تعریف کرد.
در دنیای واقعی، دیتافریم ها با فراخواندن فایل های ذخیره شده ساخته می شوند. این فایل ها میتوانند انواع مختلف فرمت های excel، xml، csv، html و غیره باشد. از بین آن ها، فرمت csv معمولا بیشتر مورد استفاده قرار می گیرد.
ساختار pandas Series نیز یک ساختار یک بعدی، و در واقع یک ستون، از داده هاست. در واقع هریک از ستون های یک دیتافریم، یک Series نیز می باشد.
نحوه استخراج اطلاعات از داده به کمک Pandas
برای بررسی اولیه یک دیتافریم، نیاز به استخراج اطلاعاتی نظیر ابعاد آن، نوع داده های درون آن، و اطلاعات آماری در مورد هرکدام از ستون های آن، داریم.
روش بدست آوردن ابعاد یک دیتافریم با استفاده از دستور .shape و به شکل زیر است :
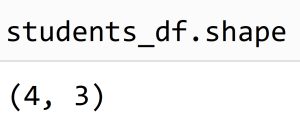
در سلول بالا، خروجی شامل ابعاد دیتافریم به شکل (rows, columns) می باشد. دقت شود که row به معنی سطر، و column به معنی ستون است.
برای بررسی نوع داده های هر ستون میتوان دستور .info() را به کار برد :
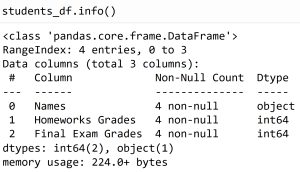
دربالا و در خروحی دستور .info()شاهد اطلاعات زیر هستیم :
- قسمت Column : نام هر ستون
- قسمت Non-Null Count : تعداد داده های هر ستون. دقت کنید که این عدد شامل missing value ها، سطر هایی که بدون داده هستند، نمی شود. در ادامه با بررسی یک دیتای واقعی می توانید متوجه این موضوع بشوید.
- قسمت Dtype : نوع داده های هر ستون. اگر صرفا این مورد را نیاز داشته باشیم، می توان از دستور .dtypes نیز استفاده کرد.
- قسمت dtypes : برای هرکدام از type ها، تعداد ستون هایی با آن نوع از داده ها نمایش داده شده است.
همچنین برای استخراج اطلاعات آماری در مورد دیتافریم، از دستور .describe() میتوان استفاده نمود :
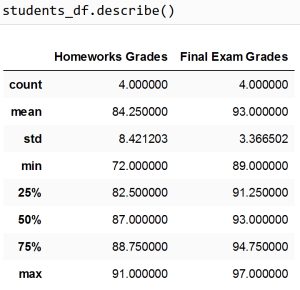
در خروجی این دستور، مقادیر آماری برای هرکدام از ستون ها را می توان مشاهده کرد. این مقادیر شامل تعداد دادههای هر ستون (مشابه دستور .info())، مقادیر میانه، میانگین، مینیمم، ماکزیمم، انحراف معیار و … می باشد.
همچنین برای مشاهده ی سطرهایی از دیتا به جهت بدست آوردن دیدگاهی کلی نسبت به آن نیز معمولا از دستورات .head()، .tail()، و .sample() استفاده می شود. البته برای اینکه متوجه تفاوت های این دستورات شوید نیاز به دیتاست بزرگتری داریم، به همین جهت آن ها را در بخش بعدی مورد بررسی قرار می دهیم.
مثال بر روی یک دیتای واقعی
(توضیحات مربوط به دیتا را در انتهای مطالب این جلسه می توانید مشاهده کنید)
ابتدا با استفاده از دستور pd.read_csv دیتا را به صورت دیتافریم وارد محیط پایتون می کنیم. در صورتی که فرمت فایل مورد نظر متفاوت باشد، میتوان از سایر دستورات مشابه نظیر pd.read_xml، pd.read_html، pd.read_excel، و غیره استفاده نمود.
![]()
در سلول بالا، نام فایل مورد نظر را به عنوان ورودی به دستور pd.read_csv داده شده است. این نام می تواند یک آدرس در داخل سیستم، و یا آدرسی بر روی اینترنت باشد، و خواندن آن ازین جهت تفاوتی ندارد.
در ادامه به بررسی دیتای مورد نظر می پردازیم.

دیتای مورد بحث، شامل 891 سطر و 12 ستون است.
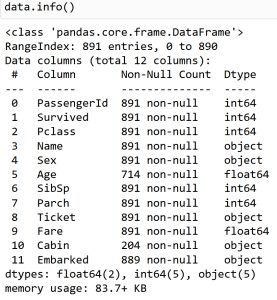
در بالا نام هریک از ستون ها، تعداد سطور دارای مقدار برای هر ستون، و نوع داده های هر ستون قابل مشاهده است.
اگر به اطلاعات ستون های Age، Cabin، و Embarked توجه کنید، مشاهده میکنید که تعداد سطرهای دارای مقدار برای هرکدام، کمتر از تعداد سطور کل دیتا (891) است. به طور مثال، در ستون Age، فقط 714 داده وجود دارد، و برای باقی سطرهای هیچ مقداری ثبت نشده است. از ویژگی های مهم Pandas، همین قابلیت بررسی missing value ها، و اعمال تغییرات دلخواه بر روی آن هاست، که در جلسات آینده با آن ها آشنا می شویم.
با توجه خروجی دستور .info()، دیتا مورد بررسی دارای دو ستون با تایپ داده ی float، 5 ستون با تایپ int (integer)، و 5 ستون با تایپ object است. لازم به ذکر است که تایپ object معادل string است.
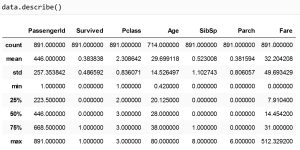
در بالا اطلاعات آماری ستونهای دیتا را می توان مشاهده کرد. اگر به نام ستونها دقت کنید، و آنها را با سلول قبلی مقایسه کنید، متوجه خواهید شد که در اینجا فقط نام ستونهایی را میبینید که نوع دادههای آن ها عددی است (int یا float)، و هیچ اطلاعاتی در مورد ستون های دیگر وجود ندارد. برای اینکه اطلاعاتی در مورد سایر ستون های دیتا مشاهده کنیم، باید در دستور .describe()، مقدار include را برابر ‘all’ قرار دهیم:
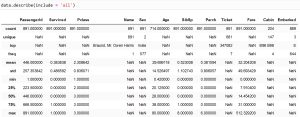
در جدول بالا، علاوه بر ستون های عددی، اطلاعاتی در مورد باقی ستون ها نیز وجود دارد.
این خروجی نسبت به خروجی سلول قبلی، سه سطر اضافه دارد. مقدار uniqueبرای هر ستون، در واقع تعداد مقادیری است که حداقل یکبار تکرار
شده اند. top، نشان دهنده ی مقداری با بیشترین تکرار در هر ستون است، و freq تعداد تکرار آن را نشان می دهد. برای ستون های عددی نیز هیچکدام ازین 3 مورد تعریف نشده اند.
به طور مثال، ستون Embarked شامل 3 مقدار متفاوت است، و از بین این مقادیر، مقدار ‘S’ بیشترین تکرار را دارد، که همانگونه که مشاهده می شود، در این ستون 644 سطر دارای مقدار ‘S’ هستند.
خواندن سطرهای ابتدا، انتها، و تصادفی از دیتا
همان طور که در بخش قبلی اشاره شد، برای مشاهده ی سطرهایی از دیتا، می توان از دستورات .head()، .tail()، و .sample() استفاده نمود.
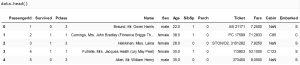
در بالا با استفاده از دستور .head()، که برای نشان دادن سطرهای ابتدایی مورد استفاده قرار میگیرد، 5 سطر بالای این دیتا را می توان مشاهده کرد. این دستور و دستورات .tail() و .sample() میتوانند مقادیر int را به عنوان ورودی دریافت کنند، که تعیین کننده تعداد سطوری است که باید نشان دهند.

به طور مثال در بالا به دستور .tail() عدد 3 را به عنوان ورودی داده ایم، و خروجی 3 سطر انتهایی دیتا مورد بررسی است. به طور کلی این دستور سطور انتهایی را به عنوان خروجی می دهد.
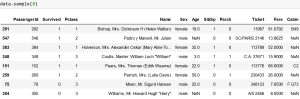
همچنین دستور .sample() به صورت رندوم سطرهایی از دیتاست را به عنوان خروجی می دهد. دقت کنید که مقدار پیش فرض ورودی این دستورات عدد 5 می باشد.
برای دسترسی به دیتاست بالا به این لینک مراجعه کنید :
و برای دسترسی به کدهای جلسه ی اول و سایر جلسات به این لینک مراجه کنید :
در جلسه ی بعد، نحوه ی انتخاب سطرها و ستون ها دلخواه از یک دیتافریم، و چگونگی کار با index را مورد بحث قرار می دهیم.
خلاصه ای در مورد دیتا
دیتای مورد بررسی که شامل اطلاعات مسافران کشتی Titanic است، یکی از معروفترین دیتاست ها برای شروع یادگیری مباحث علم داده و یادگیری ماشین می باشد. همچنین این دیتا مربوط به یکی از مسابقات سایت Kaggle است، که نسخه ی مورد بررسی از این سایت دانلود شده است.
همان طور که مشاهده کردید این دیتا شامل 12 ستون است که هرکدام اطلاعات زیر را به ما می دهد:
PassengerId : ردیف مسافر در لیست
Survived : عدد 1 نشان دهنده ی این است که مسافر نجات یافته است، و صفر نشان دهنده ی فوت مسافر است
Pclass : درجه ی امکانات مسافر، 1 بالاترین درجه است
Name : نام مسافر
Sex : جنسیت مسافر
Age : سن مسافر
SibSp : تعداد خواهر / برادر / نامزد مسافر که در کشتی حضور داشتند
Parch : تعداد والدین / فرزندان مسافر که در کشتی حضور داشتند
Ticket : شماره بلیط مسافر
Fare : کرایه مسافر
Cabin : شماره کابین
Embarked : بندری که مسافر از آن سوار شده است
در ادامه، مطالب هر جلسه را بر روی این دیتا پیاده سازی و بررسی خواهیم کرد.
موفق و پیروز باشید.
نویسنده : مصطفی جهانیان، عضو تیم IMT
برای دیدن سایر مطالب سایت کلیک کنید.




پاسخها