
لرنینگ (Learning) در هوش مصنوعی چیست؟
تنها واژهای (دلیلی) که باعث رشد چشمگیر هوش مصنوعی در هزاره جدید شده، همین اصطلاح لرنینگ یا (یادگیری) هست.
هرچند الگوریتمهایی که در هوش مصنوعی و بخصوص ماشین لرنینگ پیاده میشه از سالهای دورتر (1943 با ساخت اولین شبکه عصبی) ایجاد شدند، ولی شکل و شمایل لرنینگ در 20 سال اخیر به طرز چشمگیری توجهات تمامی زمینههای علمی، کاری، تحقیقاتی و … رو به خودش جلب کرده.
اما چیزی که خیلی مهمه اینه که:
1- دقیقا این لرنینگ چجوری صورت میگیره؟
2- تفاوت یادگیری انسان و ماشین در چیست؟
3- اصلا چیزی به اسم حفظ کردن هم در ماشین داریم؟ حفظ کردن خوبه یا بد؟
بریم تا درمورد این سوالات با هم مفصلا صحبت کنیم.
1- لرنینگ چجوری صورت میگیره؟
قبل از وارد شدن به بحث یادگیری مدل هوش مصنوعی، یه مثال ساده میزنم تا یک ذهنیتی درباره تفاوت یادگیری انسان و ماشین رو با هم داشته باشیم.
فرض کنید قراره تبدیل به یک پزشک ماهر بشید و بهترین تجویزهارو داشته باشید. برای این منظور نیاز دارید تا چندین سال در دانشگاه تحصیل کنید، بین دانشگاه در بیمارستانها یا مراکز مختلف مباحث عملی رو تجربه کنید و کم کم تبدیل به یک پزشک بشید. بخشی از آموزش شما در کتابها قرار داره و بخشی از آموزش شما در مباحث عملی. مهمترین عنصری که در پزشک بودن شما و علم شما وجود داره (دیتاها) هستن. یعنی با مقایسه متغیرهای مختلف یک شخص، بتونید تشخیص بدید که چه چیزی برای بهبودی اون شخص، لازم هست. مثلا در یک بیماری خاص، ممکنه که شما بیش از 50 فاکتور و متغیر مختلف رو از بیمارتون بخواید و این موارد رو با انجام آزمایشات مختلف بدست بیارید. بعد با بررسی عمیق این متغیرها، تصمیم میگیرید که مسیر درمان بیمار شما به چه شکلی باید باشه.
چند سال طول میکشه که تمام این مباحث رو یاد بگیرید؟ یا اصلا میشه گفت تمومی داره؟ قطعا نه.
حالا فرض کنید یک پایگاه داده یا دیتابیسی وجود داشته باشه که تمامی این اطلاعات بیماران، تجویزها و نتیجه نهایی روال درمان، داخلش وجود داشته باشه. اینجا دقیقا همونجایی هست که ماشین خودی نشون میده. (هرچند مثالی که زدم از پزشکی بود و خیلی دل و جرات میخواد این روزا با هوش مصنوعی به سمت پزشکی بری، ولی خب به قطع میتونم بگم که یکی از بزرگترین خدمات هوش مصنوعی در سالهای آتی در دنیای پزشکی خواهد بود.)
ماشین میتونه به کمک اطلاعات موجود (دیتابیس یا DataBase) شروع کنه به یادگیری. چجوری؟
به این صورت که از شما میخواد اون اطلاعات رو اول سازمان دهی کنید. یعنی به فرمتی تبدیل بشن که قابلیت خوندن توسط ماشین رو داشته باشه. به این مرحله از فرآیند کار اصطلاحا میگیم (Data PreProcessing). بعد از اینکه دیتا آماده تحویل به ماشین شد، ماشین از شما میپرسه که جنس این دادهها و نوع توزیع و فضای ابعادی متغیرها، به کدوم یکی از الگوریتمهای من (Regressions, Neural Nets, Classifications, Clustering etc) شباهت بیشتری داره؟ و بعد از تعیین یکسری فضای فرضیه، از شما میپرسه که کدوم یکی از متغیرها رو به عنوان ورودی و کدوم هارو به چشم تارگت ببینه؟
یعنی ماشین نیاز به یکسری حد و مرز داره. نیاز به مشخص کردن عوامل اصلی داره. خودش نمیتونه رو هوا یاد بگیره. این کار رو هم متخصص هوش مصنوعی که به برنامه نویسی مسلطه، میتونه پیاده کنه. بعد از اینکه حد و مرزهای مشخص شد، ماشین سعی میکنه از دیتاهای موجود یاد بگیره.
چجوری؟
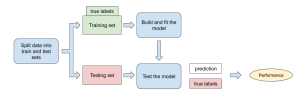
اینجاست که با اصطلاحات معروف (Train and Test) آشنا میشیم. ماشین از ما میخواد که بخشی از دادهها رو به عنوان داده Train و بخش دیگری رو به عنوان دادهی Test مشخص کنیم. همیشه میزان دادههای Train از Test بیشتره (نسبت 80 به 20 یا 90 به 10 و …). حالا ماشین سعی میکنه رابطهی بین ورودیها و تارگتهارو در دیتای Train پیدا کنه.
یه مثال میزنم که کاملا شفاف بشه. از زمینه پزشکی بگیم.
مثلا ما قرار به کمک اطلاعاتی نظیر (سایز غده، جنسیت، سن، اعتیاد، محل قرارگیری غده، فشار خون و …) تشخیص بدیم که نوع سرطان یک شخص، خوش خیمه یا بد خیم. در این مثال تمامی متغیرهای (سایز غده، جنسیت، سن، اعتیاد، محل قرارگیری غده، فشار خون و …) به عنوان ورودی و اینکه (شخص سرطان داره یه نه) به عنوان تارگت شناخته میشه.
در دادههای Train تمامی متغیرها به ماشین داده میشه و ماشین بعد از پیدا کردن روابط ذکر شده، سعی در به حافظه سپردنشون میکنه. این به حافظه سپردن به اون شکلی که ما فکر میکنیم نیست. بلکه از نگاه ریاضیاتی میتونیم بگیم که : (ماشین در نهایت به یک فرمول مشخص میرسد که این فرمول میتواند دادهها را توصیف کند و ارتباطی باشد بین ورودیها و خروجی(ها) )
خب حالا یه سوال پیش میاد. این فرمول بهترین بوده؟ چقدر دقت داشته؟ از کجا بهش اعتماد کنیم؟
و اینجاست که میریم سراغ اون قسمت از دیتاهایی که بهشون گفتیم Test data. در این مرحله، از دیتای Test برای ارزیابی استفاده میکنیم. به این صورت که صرفا از ورودیهاش کمک میگیریم، این ورودی ها رو به فرمول نهایی اکتسابی ماشین میدیم و خروجی ایجاد شده از این فرمول رو با مقادیر واقعی تارگت Test مقایسه میکنیم. هرچی این خروجی با مقدار واقعی تارگت در Test data شباهت و نزدیکی بیشتری داشته باشه، میگیم عملکرد یادگیری ماشین خوب بوده و برعکس.
شکل زیر، پروسهای که توضیح دادم رو شفاف تر نشون میده.
2- آموزش دیدن توسط یک مدل هوش مصنوعی چه مفهومی داره و نیازمند چه ابزارهایی هست؟
برگردیم به مثال و مفاهیم قبل. بنظر شما چرا مثالی از مدت زمان طولانیه مهارت پیدا کردن یک پزشک زده شد؟
از مهمترین تفاوتهای موجود بین یادگیری انسان و ماشین، سرعت یادگیریست!!
ماشین میتونه در مدت زمان بسیار کوتاهی، هزاران اطلاعات رو از ما بگیره و به خوبی حتی یاد بگیره. اما انسان برای یادگیری یک مسئله نیاز به زمان خیلی بیشتری داره. البته بازم میگم جرات و جسارت زیادی مطلبه که یک پزشک واقعی رو با یک مدل هوش مصنوعی مقایسه کرد. چرا که در حال حاضر مدلهای هوش مصنوعی به یک قدمی یک پزشک ماهر هم نرسیدند اما در آینده ممکنه شرایط متفاوت بشه (که میشه).
از طرف دیگه، انسان ها در پروسه یادگیری و استفاده کردن از یادگیری، دچار احساسات، عصبانیت، خطای محاسباتی، ندیدن پارامترهای زیاد کنار هم، خستگی و بیخیالی و … بشن. ولی ماشین اینطور نیست! هرچند ماشین هم خطاهای خاص خودش رو داره (مثل نویزها) ولی اگر فکری به حال این خطاها در برنامه نویسی بشه، دیگه مشکلی وجود نداره و راندمان نوسانی در ماشین نخواهیم دید.
ندیدن پارامترهای زیاد کنار هم؟ این قسمت از جمله بالا چه معنایی داره؟
طبق تحقیقاتی که در دانشگاه استنفورد صورت گرفته، یک انسان در یک چالش، در بهترین حالت میتونه 7 آیتم و عامل تاثیرگذار رو در نظر بگیره. مثبت و منفی 2
یعنی بین 5 تا 9. خب این خودش یه نوع محدودیته! ولی ماشین میتونه بینهایت متغیر و آیتم مختلف رو در یک مسئله کنار هم قرار بده و محاسبات خودش رو انجام بده.
و خیلی موارد دیگه مثل فراموش کردن! که این مورد خیلی مهم نیست چون فراموش کردن در دنیای ماشین ها هم وجود داره و اگر بخوایم پیش نیاد باید هزینه سنگینی واسه نگهداری از تجهیزات کنیم.
3- اصلا چیزی به اسم حفظ کردن هم در ماشین داریم؟ حفظ کردن خوبه یا بد؟
هیچوقت یادم نمیاد که به جز درسهای حفظی و امتحاناتش، جای دیگهای حفظ کردن به کمکم اومده باشه. کلا حفظ کردن ارزش کار رو پایین میاره و خیلی دارای اهمیت نیست. برعکس، یاد گرفتن یه چیز دیگست.
این موضوع دقیقا تو ماشین هم صادقه. مدل یادگیری هوش مصنوعی، اگر درگیر حفظیات بشه (Overfitting) رسما میشه گفت اون مدل بدرد نمیخوره. پس این یکی از بزرگترین چالشهایی هست که باید مراقبش باشیم که درگیرش نشیم.
یکی از راه های شناسایی این موضوع، دقت 100 درصدی مدل نهایی هوش مصنوعی هست! مدلی که 100 درصد دقت داره، ارزش پایینی داره و مدلی که دقت 98 درصدی داره (به عنوان مثال) خیلی خیلی مدل بهتریه. چون 2 درصد احتمال اشتباه داره. چون اشتباه در پس یادگیری میاد نه حفظ کردن! فلسفی شد یکم.
به هر حال، ما کلا دنبال (Machine Learning) هستیم. یعنی یادگیری ماشین! و جایی اسمی از حفظ کردن ماشین نیومده که بخوایم دنبالش باشیم، هرچند خیلی راحت هم میشه این موضوع رو کنار گذاشت.
امیدوارم با مطالعه مباحث بالا، فرآیند لرنینگ براتون جا افتاده باشه.
همیشه پیروز باشید
برای دیدن مقالات بیشتر میتونید روی لینک کلیک کنید.
نویسنده: محمدرضا مومنی




سلام عرض ادب سپاس از مقاله مفیدتون،یک سوال یعنی این دارای اهمیت زیادی هست که باید ماشین یادبگیره؟یعنی ماشینی که حفظ کنه خطاهاش بالا میره؟دیگه به نسبت ماشینی که یادمیگیره خطاهای کمتری نداره؟
محمد سبحان عزیز سلام
ماشین وقتی شروع به حفظ کردن میکنه، نسبت به دیتاهای آینده (دیتاهایی که بعدا وارد سیستم میشن تا پیش بینی بشن) عملکرد پایینی داره و نمیشه روی دقتش حساب کرد. بخاطر همین باید مدلی بسازیم که دچار خطای حفظ کردن نشه
شما در این مقاله گفتید که مدلی که %98 دقت داشته باشه بهتر از مدلی هست که %100دقت داشته باشه من با مثال پزشکی میگم خب اگه ماهانه ما ۱۰۰ بیمار داشته داشته باشیم که مدل %98درصد باید جراحیشون کنه خب اون 2 درصد می تونن خطرناک باشه اینجوری باشه یعنی هر ماه 20 بیمار از دست میدیم؟
یسری جاها مثل برخی مسائل پزشکی همین نتیجه هم یعنی عالی. چون وقتی این درصد رو با درصد واقعی در دنیا مقایسه میکنی، میبینی ممکنه 60 درصد یک نوع جراحی خاص موفقیت آمیز باشه و 40 درصد ناموفق. پس همین 98 درصد یک نوع پیروزیه. اون 2 درصد هم با یسری شرایط خاص میتونن کمک کنن
بله ،بسیار سپاسگزارم