
یادگیری با ناظر (Supervised Learning) چیست؟

(بخش اول رگرسیون)
یادگیری با ناظر (Supervised Learning) از مشهورترین زیر مجموعههای یادگیری ماشین (Machine Learning) است. برای آشنایی با یادگیری ماشین میتوانید به مقاله قبلی ما مراجعه کنید. در این مقاله قصد داریم به مفهوم یادگیری با ناظر بپردازیم.
آنچه در این مقاله خواهید آموخت:
- یادگیری با ناظر چیست؟
- یادگیری با ناظر کجا استفاده می شود؟
- نحوه عملکرد یادگیری با ناظر
- انواع شاخه های یادگیری با ناظر
- معرفی رگرسیون: پیش بینی یک تارگت پیوسته
- معرفی رگرسیون خطی
- معرفی رگرسیون غیرخطی (Polynomial Regression)
- مثالی از رگرسیون
- مفهوم تعمیم در یادگیری ماشین
- مفهوم بیش برازش (Overfitting)
یادگیری با ناظر چیست؟
در مسائل یادگیری با ناظر، ما با مجموعه دادهای شروع میکنیم که شامل نمونههای آموزشی با برچسبهای صحیح میباشند. سپس ماشین را با استفاده از دادههایی که برچسبدارند، یعنی مشخص است که در کدام دسته یا کلاس قرار دارند، آموزش میدهیم تا درنهایت برای داده جدیدالورود ، پیشبینی درستی انجام دهد.
یادگیری با ناظر کجا استفاده می شود؟
یادگیری با ناظر معمولاً در پیشبینی و یافتن روابط بین دادههای کمی استفاده میشود. این یکی از اولین تکنیکهای یادگیری است که هنوز به طور گسترده مورد استفاده قرار می گیرد. مسائلی نظیر اینکه با صرف هزینههای بیشتر در تبلیغات چقدر درآمد بیشتری کسب خواهیم کرد؟… آیا این متقاضی وام، وام را پس میذهد یا خیر؟….. فردا برای بورس چه اتفاقی می افتد؟
نحوه عملکرد یادگیری با ناظر:
برای نشان دادن نحوه عملکرد یادگیری با ناظر، فرض کنید میخواهید درآمد سالانه یک فرد را بر اساس تعداد سالهای تحصیلات عالی که گذرانده است، پیشبینی کنید. در یادگیری با ناظر، ماشین تلاش می کند تا با اجرای داده های آموزشی برچسب گذاری شده، از طریق یک الگوریتم یادگیری، رابطه بین درآمد و تحصیلات را بیاموزد.
از لحاظ فرمولی ، می خواهیم مدلی بسازیم که رابطه زیر، بین تعداد سالهای تحصیلات عالی X و درآمد سالانه مربوطه Y را تقریب بزند.
![]()
در این فرمول، (ϵ) نشان دهنده خطای کاهش ناپذیر در مدل است، که به دلیل نویز ذاتی در پدیده ها وجود دارد. پس از اینکه این تابع آموخته شد، آن را میتوان برای تخمین درآمد Y افرادی استفاده کرد که سالهای تحصیل X آنها را به عنوان ورودی داشته باشیم. به عبارت دیگر، میتوانیم مدل خود را روی دادههای تست بدون برچسب، برای تخمین Y اعمال کنیم. به طور کلی هدف از یادگیری با نظارت این است که در صورت ارائه مثال های جدید که در آن X شناخته شده و Y ناشناخته است، Y را تا حد امکان دقیق پیشبینی کنیم.
انواع شاخه های یادگیری با ناظر
یادگیری با ناظر را می توان بر اساس نوع خروجی به دو زیر مجموعه کلی تقسیم کرد: طبقه بندی(Classification) و رگرسیون(Regression).
نکته: در این مقاله صرفا درمورد رگرسیون صحبت میکنیم و در مقاله بعدی مفصلا درمورد طبقه بندی صحبت خواهد شد.
معرفی رگرسیون: پیش بینی یک تارگت پیوسته (Regression)
در رگرسیون متغیر هدف (Target variable) بصورت پیوسته است. متغیر هدف به معنای متغیر ناشناختهای است که ما به پیشبینی آن اهمیت میدهیم، و پیوستگی به این معنی است که شکاف (ناپیوستگی) در مقداری که Y میتواند بگیرد وجود ندارد. به طور مثال قیمت، وزن و قد افراد، متغیرهای پیوسته هستند. از سوی دیگر، متغیرهای گسسته فقط میتوانند تعداد محدودی از مقادیر را بگیرند برای مثال، تعداد بچههایی که انسان دارد یک متغیر گسسته است.
تکنیکهای رگرسیون از محبوبترین تکنیکهای آماری هستند که برای مدلسازی، پیشبینی و وظایف دادهکاوی مورد استفاده قرار میگیرد. به طور متوسط، متخصصان تجزیه و تحلیل تنها 2-3 نوع رگرسیون را می شناسند که معمولاً در دنیای واقعی استفاده می شود. اما واقعیت این است که بیش از 10 نوع الگوریتم رگرسیون برای انواع مختلف تحلیل طراحی شده است که هر نوع اهمیت خاص خود را دارد. هر تحلیلگر باید بداند که بسته به نوع داده و توزیع از کدام شکل رگرسیون استفاده کند. هر تکنیک رگرسیون، دارای مفروضاتی است که قبل از اجرای تجزیه و تحلیل باید آنها را رعایت کنیم. این تکنیکها از نظر نوع متغیرهای وابسته و مستقل و توزیع متفاوت هستند. معروفترین آنها شامل دو دسته است:
رگرسیون خطی (Linear regression)
رگرسیون غیر خطی (Polynomial Regression)
معرفی رگرسیون خطی
این ساده ترین شکل رگرسیون است. در این تکنیک متغیر وابسته ماهیت پیوسته دارد و رابطه بین متغیر وابسته و متغیرهای مستقل از نظر ماهیت خطی فرض میشود. در این نوع مدلسازی میتوانیم مشاهده کنیم که یک رابطه خطی بین متغیرهای مستقل و و متغیرهای وابسته وجود دارد. خط سیاه در نمودار زیر، خط رگرسیون است.
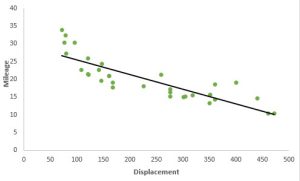
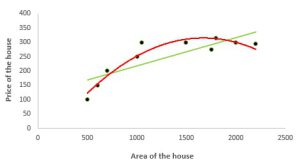
معرفی رگرسیون غیر خطی (Polynomial regression)
رگرسیون غیرخطی روشی برای یافتن یک معادله غیرخطی بین متغیرهای مستقل و متغیر هدف است. در این روش از ترکیب توابع چند جملهای غیرخطی استفاده می شود. در شکل زیر می بینید که منحنی قرمز بهتر از منحنی سبز با دادهها مطابقت دارد. بنابراین در شرایطی که رابطه بین متغیرهای وابسته و مستقل ، غیرخطی به نظر می رسد، می توانیم رگرسیون غیر خطی را به کار ببریم.
مثالی از رگرسیون
یک مسأله معروف رگرسیون کلاسیک، پیش بینی درآمد است. در این مساله، دادههای ورودی X شامل تمام اطلاعات مرتبط در مورد افراد در مجموعه دادهها است که میتوان از آن برای پیشبینی درآمد استفاده کرد. مانند سالهای تحصیل، سالهای تجربه کاری، عنوان شغل یا کدپستی. این ویژگیها features نامیده میشوند که میتوانند عددی (Numerical) مثل سالهای سابقه کار، یا طبقهای (Categorical) مثل عنوان شغل یا رشته تحصیلی باشند.
هدف ما اینست که تا آنجا که ممکن است مشاهدات آموزشی مربوط به این ویژگی ها با خروجی Y را انجام دهیم تا مدل ما بتواند رابطه بین X و Y را یاد بگیرد. دادهها به مجموعه دادههای آموزشی و مجموعه دادههای تست تقسیم می شوند. مجموعه آموزشی دارای برچسبهایی است، بنابراین مدل شما میتواند از این نمونههای برچسبدار یاد بگیرد. مجموعه تست دارای برچسب نیست، یعنی شما هنوز مقداری را که میخواهید پیشبینی کنید، نمیدانید. مهم است که مدل شما بتواند به موقعیت هایی تعمیم دهد که قبلاً با آن مواجه نشده است تا بتواند در داده های تست عملکرد خوبی داشته باشد.
Y = f(X) + ϵ
where X = (x1, x2…xn)
Training: machine learns from labeled training data
Test: machine predicts Y from unlabeled testing data
توجه داشته باشید که X می تواند با هر تعداد بُعدی باشد. مثلا مجموعه 1 بعدی که یک بردار است و از یک ستون و چندین ردیف تشکیل شده است، مجموعه 2 بعدی که یک ماتریس است که از2ستون و چندین ردیف تشکیل شده است و ه همین صورت شما می توانید مجموعه با ابعاد 3 و4 و 5 یا بیشتر داشته باشید.
ما در اینجا میخواهیم مثال ساده دو بعدی را بررسی کنیم. دیتای ما می تواند به شکل یک فایل csv باشد که در آن هر ردیف شامل سطح تحصیلات و درآمد یک فرد است. اگر ستون های بیشتری با ویژگیهای بیشتر اضافه کنید یک مدل پیچیدهتر، اما احتمالاً دقیقتر خواهید داشت.
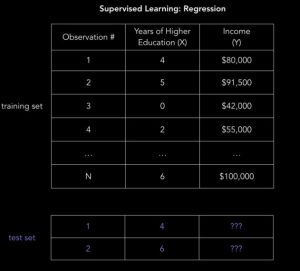
حل مساله
در اینجا ما روی حل مسئله پیشبینی درآمد با رگرسیون خطی تمرکز میکنیم. ما مجموعه داده X، و مقادیر هدف متناظر Y را داریم. هدف از رگرسیون، یادگیری یک مدل خطی است که میتوانیم از آن برای پیشبینی یک x جدید با توجه به x قبلاً دیده شده با کمترین خطای ممکن استفاده کنیم. ما میخواهیم حدس بزنیم که یک فرد بر اساس تعداد سالهایی که تحصیل کرده چقدر درآمد دارد.

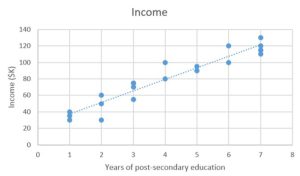
تعیین میزان خطا
از نظر ریاضی، ما به تفاوت بین هر نقطه داده واقعی (y) و پیشبینی مدل خود (j’) نگاه میکنیم. این تفاوت ها را مربع کنید تا از اعداد منفی جلوگیری کنید و تفاوت های بزرگتر را جریمه کنید و سپس آنها را جمع کنید و میانگین را بگیرید. این معیاری است که نشان می دهد داده های ما چقدر با خط مطابقت دارند.
برای یک مسئله ساده مانند این، میتوانیم با استفاده از حساب دیفرانسیل و انتگرال، پارامترهای بتا بهینه، که تابع ضرر ما را به حداقل میرسانند، بیابیم. اما با افزایش پیچیدگی یک تابع هزینه، یافتن یک راه حل با حساب دیفرانسیل و انتگرال دیگر امکان پذیر نیست.
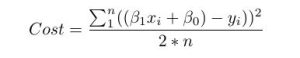
مفهوم تعمیم در یادگیری ماشین (Generalization)
وقتی در مورد همه یا بیشتر افراد یا چیزها با هم اظهار نظر می کنید، یک تعمیم می دهید. به عنوان مثال: همه پرندگان بال دارند… بسیاری از کودکان برای صبحانه غلات می خورند… . در یادگیری ماشین قدرت تعمیم بدین معناست که مدل با آموخته های خود میتواند به خوبی داده های ندیده را تشخیص دهد و آنچه را آموخته، برای دادههای ندیده تعمیم دهد. پس هرچقدر یک مدل قدرت تعمیم بیشتری داشته باشد مدل بهتری است.
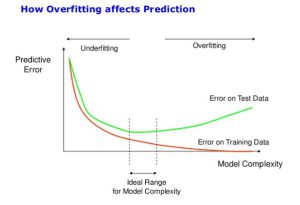
مفهوم بیش برازش (Overfitting)
یک مشکل رایج در یادگیری ماشین، بیش برازش است. بیش برازش یا تطبیق بیش از حد، زمانی اتفاق میافتد که یک مدل جزئیات و نویز در دادههای آموزشی را تا حدی بیاموزد که بر عملکرد مدل در دادههای جدید تأثیر منفی بگذارد. این بدان معنی است که نویز یا نوسانات تصادفی در داده های آموزشی به عنوان مفاهیم توسط مدل انتخاب شده و یاد می شود. هرگاه یک مدل از دادههای آموزشی بیش از حد یاد بگیرد تا جایی که شروع به انتخاب ویژگیهای خاص میکند که نماینده الگوهای موجود در دنیای واقعی نیستند. به اصطلاح در بیش برازش، مدل در حال (حفظ کردن) میباشد.
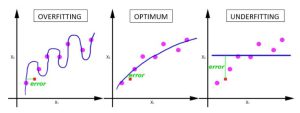
این اتفاق به ویژه زمانی که مدل خود را پیچیده تر می کنید بوجود می آید. به زبان دیگر، برازش بیش از حد مفهومی در علم داده است که زمانی اتفاق می افتد که یک مدل آماری دقیقاً با داده های آموزشی آن مطابقت داشته باشد. وقتی این اتفاق میافتد، متأسفانه الگوریتم نمیتواند به درستی در برابر دادههای دیده نشده عمل کند و قدرت تعمیم دهندگی (Generalization) در آن کاهش می یابد.
امیدوارم که مطالب این مقاله برای شما مفید بوده باشه.
نویسنده : خدیجه عابدی، عضو تیم IMT
برای دیدن سایر مقالات کلیک کنید.





پاسخها